
🎤 Introduzione
In questo post illustro come: estrarre tracce audio da filmati (usando, per esempio, YouTube), eseguire una conversione del parlato in testo (speech to text), estrarre conoscenza dal testo non strutturato della trascrizione.
Utilizzo le funzionalità di IBM Watson accessibili mediante Watson Developer Cloud e il linguaggio di programmazione Python.
La scelta di Watson non è vincolante. Funzionalità analoghe potrebbero essere ottenute utilizzando altre soluzioni comparabili come quelle fornite da:
Microsoft Azure ML Google Cloud Platform Amazon AWS MLe una pletora di servizi online come MonkeyLearn e altri. Per esempio, il riconoscimento vocale accessibile con le Speech API di Google supporta 80 lingue che è un numero ben superiore alle attuali capacità di Watson. Ciononostante, grazie anche alla varietà e profondità della sua offerta, Watson assolve sul mercato un ruolo di riferimento con cui è necessario e utile misurarsi.
🧠 Cos'è IBM Watson?
Anzitutto, che cos'è IBM Watson? Nella sua strategia di diversificazione, IBM ha sempre mostrato una particolare attenzione per l'intelligenza artificiale, anche contribuendo allo sviluppo tecnologico con passaggi importanti: nel 1997, dopo 8 anni di sviluppi, IBM Deep Blue si aggiudicò una rivincita storica a scacchi contro il campione del mondo Kasparov e nel 2011 il nuovo IBM Watson, partecipando al famoso quiz televisivo "Jeopardy!", fu in grado di battere i due campioni in carica.
Il Watson dell'edizione di "Jeopardy!" aveva alle spalle circa 6 anni di sviluppi. In essenza, Watson nasce come un sofisticato sistema di Question Answering (QA) predisposto alla comprensione del linguaggio naturale, alla generazione di ipotesi e all'apprendimento.
Un suo elemento fondamentale è il framework DeepQA che è definito come una massive parallel probabilistic evidence-based architecture e si basa sull'impiego concorrente di molteplici algoritmi di:
- Analisi della domanda in linguaggio naturale
- Ricerca delle risposte
- Classificazione delle risposte secondo la loro plausibilità
Il tutto combinato per ottenere miglioramenti consistenti nell'accuratezza, nel livello di confidenza e nella velocità di processazione.
💻 Architettura Hardware
Gli antichi latini dicevano "mens sana in corpore sano" e, il "corpo" che ospita la mente di Watson, è indubbiamente sano: i dati più recenti descrivono una griglia di 90 server basati su processori in tecnologia proprietaria POWER7 estremamente parallelizzati, per una potenza complessiva di calcolo di 80 teraFLOPS e 16 teraByte di RAM.
🌐 L'Ecosistema Watson
Per essere pienamente compreso, Watson non dovrebbe essere considerato come un supercomputer ma, più correttamente, è un ecosistema basato su:
Continui investimenti e sperimentazioni in un'ampia varietà di contesti operativi: campo finanziario, burocratico, medico, bancario, servizi governativi, viaggi e customer care, culinario
Prodotti commerciali pronti all'uso offerti da IBM come servizi a canone su cloud SaaS. Alcuni esempi: Watson Virtual Agent, Watson Explorer, Watson Analytics, Watson Knowledge Studio
Watson Developer Cloud: un esteso set di servizi cognitivi accessibili mediante API e SDK attraverso la piattaforma PaaS IBM Bluemix
Con Watson Developer Cloud, IBM declina i servizi cognitivi di Watson allo sviluppo personalizzato: aziende e sviluppatori possono aggiungere valore combinando le tecnologie di base (classificazione, conversazione, analisi del contenuto, ecc.), sfruttando i vantaggi del PaaS per tutte le necessità di scaling verticale/orizzontale.
🛠️ Prerequisiti
Prima di proseguire, ecco di cosa abbiamo bisogno:
- Un account su IBM Bluemix
- Un ambiente Python 2.7 o 3.2+ con libreria pandas installata
🎵 Estrazione delle Tracce Audio da un Video
⚠️ Attenzione! La scelta di estrarre una traccia audio da un video YouTube è da intendersi come pura sperimentazione, nel pieno rispetto delle policy Google per il download dei video e la loro diffusione.
Un modo semplice per estrarre una traccia audio da un video YouTube consiste nell'usare il tool youtube-dl. È installabile nel modo usuale per i package di Python:
pip install youtube-dl
In particolare, ho casualmente scelto il video What is Machine Learning accessibile all'indirizzo:
Il comando usato per l'estrazione è:
youtube-dl "https://www.youtube.com/watch?v=ty-kTUzMnjk" \
--extract-audio \
--audio-format wav \
--audio-quality 16K \
--id
Il codice alfanumerico ty-kTUzMnjk usato nel comando di estrazione è l'identificativo univoco del video nell'archivio di YouTube. Una volta acceduto alla pagina del video su YouTube, il codice univoco può essere recuperato dalla barra dell'indirizzo del browser o facendo click sul pulsante "Condividi".
💡 Nota: youtube-dl potrebbe richiedere l'installazione della libreria libav. Sui sistemi Debian/Ubuntu questa libreria è inclusa nel package libav-tools.
Dall'esecuzione di youtube-dl ottengo un file wav (ty-kTUzMnjk.wav) contenente la traccia audio opportunamente codificata secondo i requisiti del servizio di speech recognition.
⚙️ Predisposizione dei Servizi Watson su Bluemix
Assumendo che siamo già registrati su Bluemix, il passo successivo consiste nel configurare un set di credenziali per l'accesso a due servizi specifici:
- Speech To Text: converte la voce umana in testo scritto
- AlchemyAPI: è un insieme di API che consentono l'analisi del testo attraverso NLP (Natural Language Processing)
Mediante AlchemyAPI è possibile utilizzare diverse funzioni come:
- Estrazione di parole chiave
- Estrazione di entità
- Analisi delle opinioni
- Analisi emozionali
- Tagging concettuale
- Estrazione di relazioni
- Classificazione tassonomica
Configurazione Credenziali
Il metodo più semplice consiste, partendo dal cruscotto di Bluemix, nel fare click su "Catalogo" e scrivere nella search bar il nome del servizio. Per esempio, se scriviamo speech e facciamo click su "Filtro", il cruscotto visualizzerà un elenco di servizi incluso quello di nostro interesse: "Speech To Text".
Dalla sezione di gestione, facciamo click su "Credenziali del servizio" e quindi su "Visualizza credenziali", per ottenere le credenziali nel seguente formato:
{
"url": "https://stream.watsonplatform.net/speech-to-text/api",
"password": "V6l*******",
"username": "d6c7fe4f-6644-437f-baf2-*******"
}
Procediamo in modo analogo con il servizio AlchemyAPI:
{
"url": "https://gateway-a.watsonplatform.net/calls",
"note": "It may take up to 5 minutes for this key to become active",
"apikey": "a0e8bb2**************************"
}
🐍 Predisposizione Ambiente Python
Per l'accesso ai servizi di Watson Developer Cloud è disponibile il package Watson Developer Cloud Python SDK installabile nel modo usuale:
pip install --upgrade watson-developer-cloud
🗣️ Conversione della Voce in Testo
Il blocco di codice seguente include le istruzioni per richiedere al servizio Speech to Text la processazione del file wav precedentemente generato:
import json
from os.path import join, dirname
from watson_developer_cloud import SpeechToTextV1
import pickle
speech_to_text = SpeechToTextV1(
username='d6c7fe4f-6644-437f-baf2-*******',
password='V6l*******',
x_watson_learning_opt_out=False
)
filename='./ty-kTUzMnjk'
with open(filename+'.wav', 'rb') as audio_file:
results=speech_to_text.recognize(audio_file,
content_type='audio/wav',
continuous=True,
timestamps=True,
word_confidence=True,
profanity_filter=False,
word_alternatives_threshold=0.4)
pickle.dump(results, open(filename+'.watson.p','wb'))
Parametri di Configurazione
L'oggetto fondamentale è l'istanza speech_to_text della classe SpeechToTextV1. Alla funzione recognize è necessario passare alcuni parametri:
Obbligatori:
audio_file: contenuto del file audiocontent_type='audio/wav': formato audio
Opzionali:
timestamps=True: per ottenere i timestamp inizio/fine della parolaword_confidence=True: per attribuire ad ogni parola un grado di confidenzaprofanity_filter=False: per disattivare la censura automaticaword_alternatives_threshold=0.4: soglia minima di confidenzacontinuous=True: per il riconoscimento continuo
📊 Elaborazione della Risposta di Watson
La risposta del servizio Speech to Text è una codifica JSON. Per semplificare il recupero dei dati, uso la funzione parse_transcript:
def parse_transcript(data):
"""
data (dict): as derived from standard Watson API JSON
returns: two dicts of lists of dicts:
{
words: [],
lines: []
}
"""
lines = []
words = []
prev_line_end = 0
line_results = data['results']
for linenum, result in enumerate(line_results):
if result.get('alternatives'):
lineobj = result.get('alternatives')[0]
word_timestamps = [o for o in lineobj['timestamps'] if o[0] != '%HESITATION']
if word_timestamps:
linewords = []
word_confidences = [o for o in lineobj['word_confidence'] if o[0] != '%HESITATION']
prev_word_end = 0
for wordpos, txtobj in enumerate(word_timestamps):
word = {}
word["line_position"] = wordpos
word["line_number"] = linenum
word['confidence'] = round(word_confidences[wordpos][1], 3)
word["text"] = txtobj[0]
word["start"] = txtobj[1]
word["end"] = txtobj[2]
word["audible_duration"] = round(word["end"] - word["start"], 2)
word["pregap"] = round(word["start"] - prev_word_end, 2)
prev_word_end = word["end"]
linewords.append(word)
words.extend(linewords)
line = {}
line['line_number'] = linenum
line['start'] = linewords[0]['start']
line['end'] = linewords[-1]['end']
line['text'] = " ".join([w['text'] for w in linewords])
line['audible_duration'] = round(line['end'] - line['start'], 2)
line['confidence'] = round(lineobj['confidence'], 3)
line['word_count'] = len(words)
lines.append(line)
return {'lines': lines, 'words': words}
Conversione in DataFrame
import pandas as pd
data = parse_transcript(results)
lines = pd.DataFrame(data['lines'])
words = pd.DataFrame(data['words'])
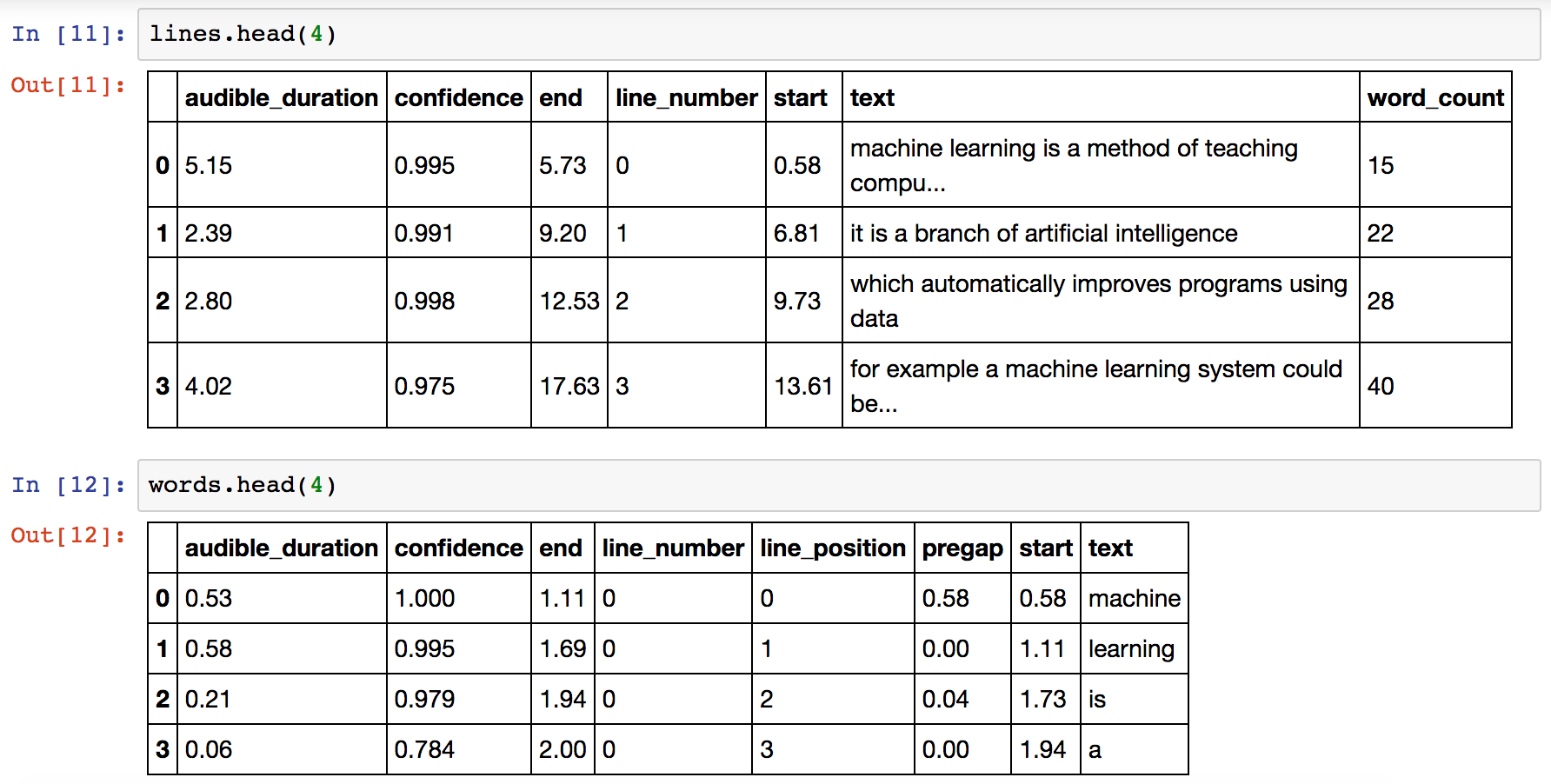
Struttura dei Dati
DataFrame lines (per ogni frase riconosciuta):
audible_duration: durata in secondi della fraseconfidence: grado di confidenza complessivo sulla frasestart/end: timestamp di inizio/fine fraseline_number: indice numerico univoco della frasetext: testo della fraseword_count: numero totale delle parole riconosciute
DataFrame words (per ogni parola riconosciuta):
audible_duration: durata in secondi della parolaconfidence: grado di confidenza sulla parolastart/end: timestamp di inizio/fine parolaline_number: indice della frase di appartenenzaline_position: posizione della parola nella frasetext: testo della parolapregap: intervallo di silenzio dalla parola precedente
Trascrizione Completa
L'intera trascrizione può essere ottenuta con:
transcript = "\n".join((lines['text']).tolist())
print(transcript)
Output:
machine learning is a method of teaching computers to make predictions based on some data
it is a branch of artificial intelligence
which automatically improves programs using data
for example a machine learning system could be trained on email messages
to learn to distinguish between spam and non spam messages
after learning it can be used to classify new email messages into spam and non spam folders
various fields where machine learning is frequently used our medical diagnosis
brain machine interfaces
chem informatics
self driving cars
stock market analysis
a recommendation engine using machine learning could be used to recommend the right product to the right customer
over time as more data is added and used by the algorithm the performance of the system improves
🧮 Analisi del Testo attraverso NLP
Il blocco di codice seguente include le istruzioni per richiedere al servizio AlchemyAPI elaborazioni specifiche della trascrizione:
import json
from os.path import join, dirname
from watson_developer_cloud import AlchemyLanguageV1
alchemy_language = AlchemyLanguageV1(api_key='a0e8bb2**************************')
# get entity, keyword, taxonomy, concepts with a single call
comb = alchemy_language.combined(text=transcript, sentiment=True)
concepts = pd.DataFrame(comb['concepts'])
keywords = pd.DataFrame(comb['keywords'])
taxonomy = pd.DataFrame(comb['taxonomy'])
language_detection = comb['language']
target_phrases = ['machine learning', 'spam',
'stock market analysis',
'recommendation engine',
'right product',
'right customer'
'data',
'predictions']
# get targeted sentiment
res_targ_sent = alchemy_language.targeted_sentiment(text=transcript,
targets=target_phrases,
language='english')
target_sent = pd.DataFrame(res_targ_sent['results'])
# get targeted emotion
res_targ_emot = alchemy_language.targeted_emotion(text=transcript,
targets=target_phrases,
language='english')
target_emot = pd.DataFrame(res_targ_emot['results'])
# get document emotion
emot = alchemy_language.emotion(text=transcript)
# get typed relations
relat = alchemy_language.typed_relations(text=transcript)
Funzioni di Analisi Implementate
- Estrazione di parole chiave: individuazione delle parole chiave nel testo con grado di rilevanza e analisi del sentiment
- Tagging concettuale: identifica concetti generali correlabili al testo
- Classificazione tassonomica: classifica il contenuto in una gerarchia di categorie
- Analisi emozionale: analizza emozioni specifiche (Rabbia, Paura, Gioia, Tristezza, Disgusto)
- Analisi del sentiment: sentiment di frasi target e del testo complessivo
- Relazioni tra entità: individuazione delle relazioni di dipendenza tra entità
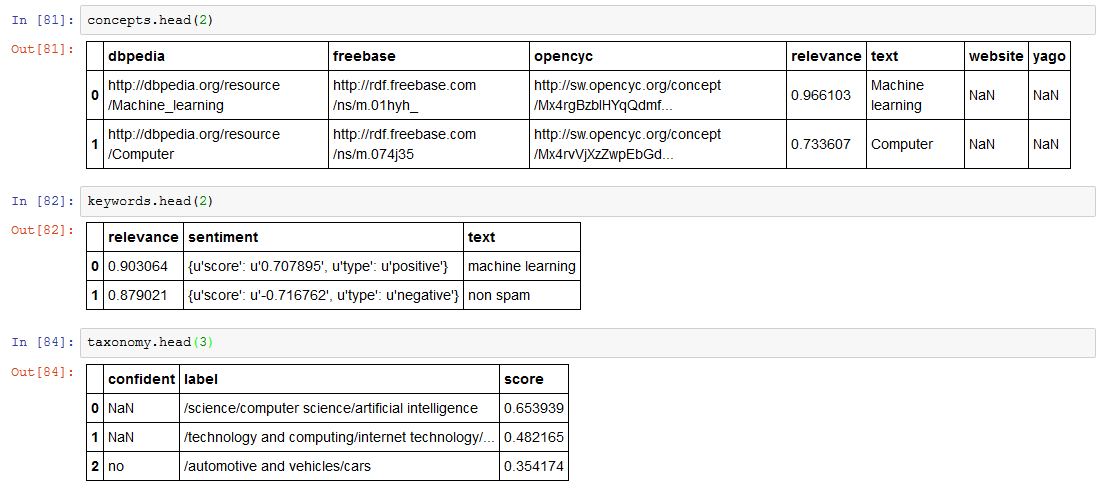
Risultati dell'Analisi
Concetti individuati (in ordine di rilevanza): Machine learning, Computer, Learning, Artificial intelligence, E-mail spam, Cognitive science, Psychology, Scientific method, Computer science, E-mail, Intelligence, Artificial neural network, Alan Turing, Education, Skill, Algorithm, Computer program, Computer vision, Debut albums, Knowledge, Marketing, Fuzzy logic, Information theory, Computational intelligence, Data, Bayesian network, Natural language processing, Stock, Cybernetics, Engine, Medical diagnosis, Machine, Right-wing politics
Parole chiave individuate (in ordine di rilevanza): machine learning, non spam, non spam folders, non spam messages, email messages, new email messages, stock market analysis, artificial intelligence, chem informatics, recommendation engine, various fields, medical diagnosis, brain machine, right product, right customer, data, predictions, example, algorithm, branch, method, computers, interfaces, programs, self, cars
Tassonomia: Watson ha correttamente inquadrato l'argomento centrale, assegnando il punteggio più alto alla classificazione /science/computer science/artificial intelligence. Compare anche /technology and computing/internet technology/email con punteggio più basso a causa dei riferimenti al riconoscimento spam.
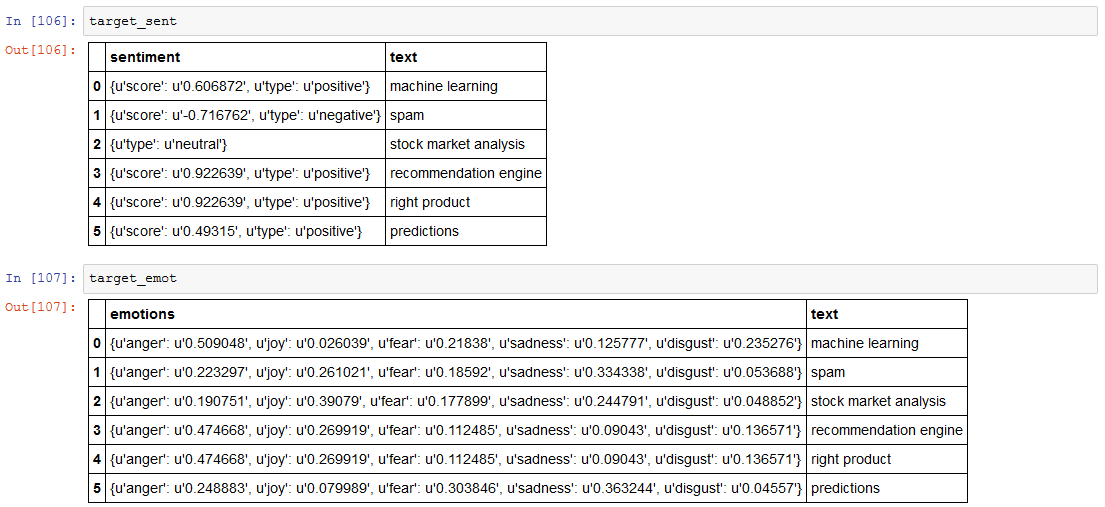
Analisi Sentiment ed Emotion
Risultati interessanti dall'analisi delle frasi target:
- Alla parola spam è stato associato un sentiment negative e una emotion sadness
- Il sentiment è neutral sulla parola stock market analysis con una emotion joy
Sentiment complessivo del documento:
{
"anger": "0.515118",
"joy": "0.140224",
"fear": "0.207606",
"sadness": "0.097711",
"disgust": "0.125342"
}
Relazioni Tipizzate
Watson ha identificato che nel testo l'entità customer è influenzata (affectedBy) dall'entità recommend, qualificando:
- customer come Person
- recommend come EventCommunication
Questo tipo di analisi è particolarmente utile per la costruzione di agenti virtuali, chatbot e sistemi che devono capire il contesto dell'interazione.
💰 Aspetto Economico
È interessante valutare l'impatto economico dell'impiego di questi servizi:
Speech to Text: contabilizzato per tempo di impiego (circa 0,02€/Minuto)
- Per la traccia audio in esame: circa 0,04€
AlchemyAPI: contabilizzato per numero di chiamate (0,00526€/Eventi)
- Per le informazioni usate in questo post (5 chiamate): circa 0,02€
- Bonus: le prime 1000 chiamate giornaliere sono gratuite per Organizzazione
Il pricing scala al ribasso in base alla quantità di chiamate. Per esempio, per più di 5 milioni di chiamate il prezzo diventa 0,00015€/Eventi.
🔍 Conclusioni e Applicazioni Future
I tempi di interazione con un sistema come Watson sono molto bassi e le modalità di comunicazione sul piano programmatico sono semplificate al massimo. Cloud + API generation + ML elevano la qualità dell'interazione uomo-macchina ad un livello fatto di dati ed obiettivi.
Potenziali Applicazioni
Una struttura dati come il DataFrame words - in cui per ogni parola riconosciuta è registrata la sua posizione (timestamp inizio/fine) nel flusso audio - apre a operazioni innovative:
Ricerca audio/video con query testuali: cercare occorrenze di parole ottenendo timestamp utilizzabili per estrarre blocchi di fotogrammi specifici
Gestione file multimediali intelligente: categorizzazione e recupero automatico basato sul contenuto reale
Sistemi di sorveglianza avanzati: individuazione e recupero automatizzato di porzioni di registrazioni attraverso filtri testuali complessi
Applicazioni marketing: analisi sentiment e contenuto di materiale audio/video su larga scala
Siamo su un piano di gestione dei file multimediali (dati non strutturati per definizione) dove categorizzazione e recupero possono essere fatti automaticamente in base al reale contenuto. Le possibilità di impiego sono veramente enormi. Ciò che apprezzo non è solo la vastità dei problemi che si possono indirizzare, quanto la facilità con cui si possono assemblare soluzioni altamente scalabili sia tecnicamente sia economicamente.