
Introduction
Squeezed into a set of short tips and schemes, a cheat sheet is not only a source for visual inspiration but also a quick way to learn something new, as well as to refresh your knowledge about any particular subject.
Here's a collection of cheat sheets of Machine Learning. Enjoy it and don't forget to bookmark this page for quick access to this exclusive cheat sheet list.
Let's start!
Microsoft Azure Machine Learning Algorithm Cheat Sheet
The Microsoft Azure Machine Learning Algorithm Cheat Sheet helps to choose the right machine learning algorithm. It includes some generalizations, oversimplifications and there are lots of algorithms not listed, but it also provides "breadcrumbs" to follow the safe direction. There are different revisions of this cheat sheet, whereas this is the version that I suggest for the moment:
scikit-learn Algorithm Cheat Sheet
scikit-learn developers tried to do some sort of flow chart on how to do machine learning. Here's the resulting picture:
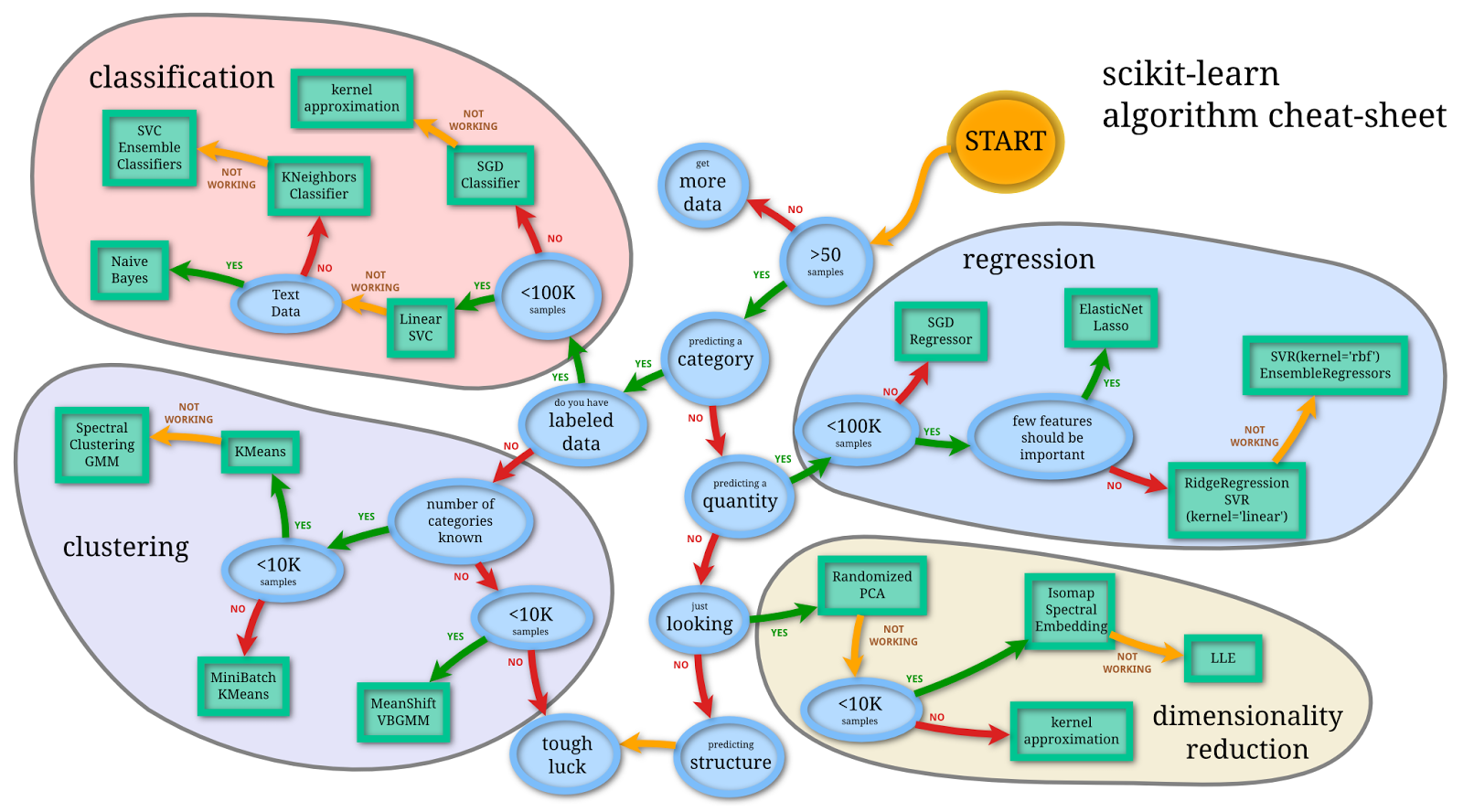
In the previous picture with ensemble classifiers/regressors we mean random forests, extremely randomized trees, gradient boosted trees and AdaBoost classifier.
Note: Boosting means that each tree is dependent on prior trees, and learns by fitting the residual of the trees that preceded it. Thus, boosting in a decision tree ensemble tends to improve accuracy with some small risk of less coverage.
Algorithm Comparison Table
The table below includes some useful information in order to choose an algorithm: each algorithm has been analyzed from the perspective of accuracy, training time, linearity, number of (hyper)parameters and other peculiarities (e.g. memory footprint and required dataset size).
Two-class Classification
| Algorithm | Accuracy | Training Time | Linearity | Parameters | Notes |
|---|---|---|---|---|---|
| logistic regression | ○ | ▲ | ▲ | medium | |
| decision forest | ▲ | △ | ○ | medium | |
| decision jungle | ▲ | △ | ○ | medium | low memory footprint |
| boosted decision tree | ▲ | △ | ○ | medium | large memory footprint |
| neural network | ▲ | ○ | ○ | high | |
| averaged perceptron | △ | △ | ▲ | low | |
| support vector machine | ○ | △ | ▲ | medium | good for large feature sets |
| locally deep support vector machine | △ | ○ | ○ | high | good for large feature sets |
| Bayes' point machine | ○ | △ | ▲ | low |
Multi-class Classification
| Algorithm | Accuracy | Training Time | Linearity | Parameters | Notes |
|---|---|---|---|---|---|
| logistic regression | ○ | ▲ | ▲ | medium | |
| decision forest | ▲ | △ | ○ | medium | |
| decision jungle | ▲ | △ | ○ | medium | low memory footprint |
| neural network | ▲ | ○ | ○ | high | |
| one-v-all | – | – | – | – | see properties of the two-class method selected |
Regression
| Algorithm | Accuracy | Training Time | Linearity | Parameters | Notes |
|---|---|---|---|---|---|
| linear | ○ | ▲ | ▲ | medium | |
| Bayesian linear | ○ | △ | ▲ | low | |
| decision forest | ▲ | △ | ○ | medium | |
| boosted decision tree | ■ | △ | ○ | medium | large memory footprint |
| fast forest quantile | ▲ | △ | ○ | high | distributions rather than point predictions |
| neural network | ▲ | ○ | ○ | high | |
| Poisson | ○ | ○ | ▲ | medium | technically log-linear; for predicting counts |
| ordinal regression | ○ | ○ | ○ | low | for predicting rank-ordering |
Anomaly Detection
| Algorithm | Accuracy | Training Time | Linearity | Parameters | Notes |
|---|---|---|---|---|---|
| support vector machine | △ | △ | ○ | low | especially good for large feature sets |
| PCA-based anomaly detection | ○ | △ | ▲ | low | |
| K-means | ○ | △ | ▲ | medium | a clustering algorithm |
Legend:
- accuracy: algorithm's "ability" to produce correct predictions with reference to all examined cases
- training time: time required to train a model
- linearity: linear classification algorithms assume that classes can be linearly separated
- number of parameters: defines the degrees-of-freedom to tune the underlying algorithm
- symbol ▲ means excellent accuracy, fast training times, and linearity usage
- symbol △ means good accuracy and moderate training times
Programming Cheat Sheets
For Python and R programmers the cheat sheet below could be a timesaver:
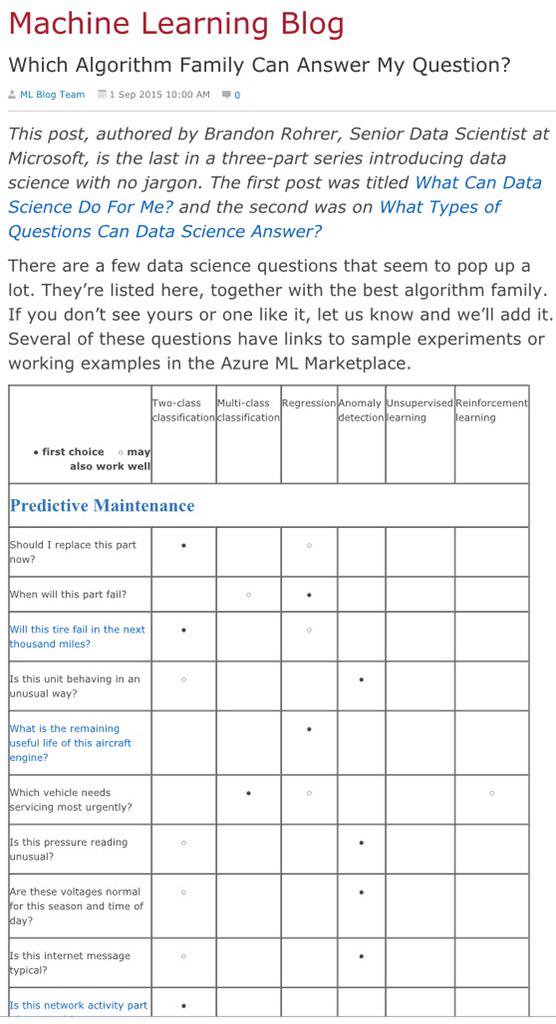
Which Algorithm Can Meet My Needs?
To answer this question, a comprehensive table is shown in the following picture:
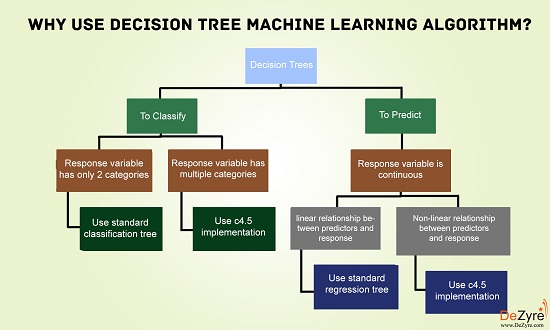
Decision Trees Guide
If you are planning to use decision trees, then you should have a look to this figure:
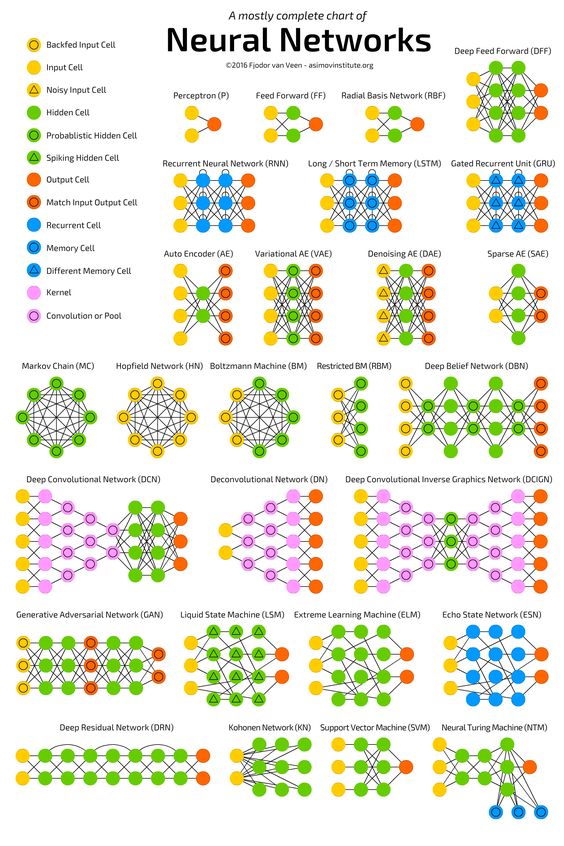
Neural Network Topologies
There are many artificial neural networks (ANN) types. Topology of a neural network refers to the way that neurons are connected, and it is an important factor in network functioning and learning. If you need an overview of ANN topologies, the following picture could be helpful:
Additional Resources
Another resource, quite basic but good, is the post Machine Learning for Dummies Cheat Sheet; also, I have particularly found useful the "Locating the algorithm you need for Machine Learning" table which provides the online location for information about the algorithms (both Python and R) used in machine learning.
If you have other "on-topic" cheat sheets, please feel free to leave a comment. I will be more than happy to take into account your suggestions.