
Ci sono molti strumenti che permettono di identificare un oggetto in un'immagine, come ad esempio il modello bag of visual words, tramite i descrittori di feature SIFT (scale-invariant feature transform) o SURF (speeded up robust feature), oppure l'utilizzo delle macchine a vettori di supporto (SVM, support vector machine); tuttavia, in questi ultimi anni, le reti neurali profonde (DNN, deep neural networks) hanno contribuito con un nuovo impulso alla ricerca e sono, pertanto, sempre più utilizzate. Infatti, l'abilità delle DNN nell'apprendere, a partire da grandi insiemi di esempi, funzioni complesse, non-lineari e ad alta dimensionalità, le rende perfette candidate per i compiti di riconoscimento di immagini. Un tipo particolare di DNN sono le reti neurali convoluzionali (CNN, convolutional neural networks) usate con grande successo per problemi di riconoscimento automatico di pattern bidimensionali come la rivelazione di oggetti, facce e loghi nelle immagini. In questo post introduco alcune specifiche implementazioni di CNN in grado di offrire un'elaborazione cognitiva delle immagini che è molto prossima allo stato dell'arte. Il codice esemplificativo è basato sull'impiego del framework MXNet in combinazione con il linguaggio Python.
MXNet è un progetto open source, distribuito con Apache License Version 2.0, frutto della collaborazione di gruppi di ricerca e sviluppo facenti capo ad importanti istituti quali CMU, NYU, NUS e MIT. MXNet è un progetto del DMLC un gruppo di aziende, laboratori e università impegnate in realizzazioni che contribuiscono da anni a definire lo stato dell'arte in materia di machine learning.
MXNet è essenzialmente un framework per l'implementazione di soluzioni di apprendimento profondo (deep learning), è sviluppato nativamente in C++ e include interfacce verso i linguaggi e ambienti più diffusi (p.e. Python, Go, R, Matlab, ecc.). Esso può essere eseguito efficientemente sia su CPU sia su sistemi ad alte prestazioni basati su GPU/Cuda, può scalare su architetture distribuite, è sufficientemente leggero per funzionare su dispositivi mobile. È anche parte integrante di altri framework come per esempio Turi.
MXnet si fonda su un connubbio tra due modelli di programmazione: la programmazione imperativa (imperative programming) e la programmazione dichiarativa o simbolica (symbolic programming). La programmazione dichiarativa consente di implementare facilmente prototipi svincolati dalla particolare natura del dato grezzo conferendo maggiore genericità ai modelli risultanti. Un'introduzione a MXnet è fornita nel documento MXNet: A Flexible and Efficient Machine Learning Library for Heterogeneous Distributed System.
Nell'arsenale di MXNet sono incluse molte implementazioni per la creazione di CNN (in parte utilizzate anche in questo post).
Prima di tutto: i dati!
Una collezione di riferimento, liberamente accessibile, per lo sviluppo di algoritmi di processazione di immagini è ImageNet. Questa collezione ha una dimensione che è di gran lunga più grande di qualsiasi altra cosa disponibile nella comunità della computer vision e sta contribuendo allo sviluppo di algoritmi di riconoscimento finemente addestrati che non avrebbero potuto essere altrimenti prodotti.
ImageNet è infatti un imponente archivio di immagini catalogate in categorie e sottocategorie che raccoglie oltre 14 milioni di immagini diverse indicizzate in 21K+ categorie. Per organizzare questa enorme collezione di immagini è usato il database di vocaboli inglesi WordNet. La catalogazione delle immagini è eseguita manualmente attraverso il sistema Mechanical Turk di Amazon che consente di organizzare migliaia di esseri umani per eseguire compiti di piccola entità.
ILSVRC - ImageNet Large Scale Visual Recognition Competition
Ogni anno la competizione ILSVRC (ImageNet Large Scale Visual Recognition Competition) invita le persone che lavorano nel campo della computer vision a misurare i progressi fatti nel riconoscimento e classificazione automatica delle immagini. I sistemi in competizione sono prima collaudati su sottoinsiemi arbitrariamente grandi di immagini già correttamente etichettate (provenienti da ImageNet) e poi sono chiamati ad etichettarne altre mai viste, infine, durante un workshop che si svolge dopo la competizione, i vincitori condividono e discutono le loro tecniche. Nel 2010 il sistema che vinse era in grado di etichettare correttamente il 72% delle immagini (per gli esseri umani la media era del 95%). Nel 2012 un'équipe guidata da Geoffrey Hinton, dell'università di Toronto, ha raggiunto un livello di precisione dell'84% grazie all'apprendimento profondo. Quest'innovazione ha prodotto rapidi miglioramenti e un'accuratezza del 96% nell'ImageNet Challenge del 2015, l'edizione in cui le macchine hanno superato per la prima volta gli esseri umani.
Il gruppo DMLC rende disponibili reti CNN già addestrate su subset di ImageNet. Come vedremo, questi modelli sono usabili anche con MXNet e ciò può essere un grande vantaggio in quanto l'addestramento su copiose collezioni di immagini è sempre un compito oneroso in termini computazionali, temporali ed economici.
Prossimi passi
Per semplificare, ho organizzato questo post in due sezioni. Nella prima sezione illustro come utilizzare i modelli pre-addestrati di DMLC ottenendo, con minimo sforzo, sistemi di classificazione delle immagini che sono allo stato dell'arte. Nella seconda sezione accenno alle caratteristiche architetturali delle reti CNN e propongo un'implementazione from scratch di una rete CNN basilare in grado di riconoscere immagini appartenenti a due categorie specifiche: cat e airplane.
Caricamento di modelli pre-addestrati allo stato dell'arte
Nel blocco seguente: carico il modello model_21k che è pre-addestrato sull'intero dataset ImageNet (14M+ immagini in 21K+ categorie).
Il caricamento è avviato eseguendo la funzione mx.model.FeedForward.load e specificando i parametri prefix che è una stringa arbitraria usata per generare dinamicamente i nomi dei file (p.e. prefix-symbol.json e prefix-{epoch}.params) in cui sono memorizzati i parametri da caricare e iteration che è il numero dell'epoca (epoch) in cui sono stati generati i parametri. Un'epoca è semplicemente un'unità di misura per l'allenamento di una rete neurale. Si può pensare di allenare la propria rete per un certo numero di epoche e verificare al termine se l'allenamento ha prodotto buoni risultati o meno. Solitamente, durante l'addestramento di una rete neurale, i parametri appresi sono memorizzati periodicamente su disco (p.e. al termine di ogni epoca, ogni 10 epoche, ecc.). Per la rete in esame, DMLC fornisce l'addestramento all'epoca nona, quindi, imposto num_round = 9 per caricare il modello all'epoca data.
Per poter ottenere delle classificazioni human-readable carico in memoria anche la lista synset che associa l'indice numerico progressivo assegnato ad ogni categoria ad un elenco di parole che la descrivono. Questa lista è usata per tradurre l'output della rete (un elenco di indici numerici corrispondenti alle classi con relativa probabilità) in un elenco pesato di parole comprensibili.
Le immagini da riconoscere devono soddisfare specifici requisiti dettati dalla rete e sono quindi elaborate mediante un'apposita funzione di pre-processazione preprocessing.PreprocessImage_21k.
La predizione è eseguita invocando la funzione model.predict.
# import mxnet
import mxnet as mx
# import image preprocessing functions
import preprocessing
# pretrained model file settings
prefix = "./datasets/preloaded/model_21k/Inception"
# get the ninth epoch
num_round = 9
# load model
model = mx.model.FeedForward.load(prefix=prefix, iteration=num_round)
# load textual tags for each classes
# used below to translate the predicted classes in a human-readable way
synset = [l.strip() for l in open('./datasets/preloaded/model_21k/synset.txt').readlines()]
# test image preprocessing
batch = preprocessing.PreprocessImage_21k('./test-images/candle.jpg', True)
# batch = preprocessing.PreprocessImage_21k('./test-images/funny-cat.jpg', True)
# get prediction probability of 1000 classes from model
prob = model.predict(batch)[0]
# argsort, get prediction index from largest prob to lowest
pred = np.argsort(prob)[::-1]
# get top1 label
top1 = synset[pred[0]]
print("Top1: ", top1)
# get top5 label
top5 = [synset[pred[i]] for i in range(5)]
print("Top5: ", top5)
Per stimolare i modelli pre-addestrati utilizzo le seguenti immagini:


Risultato della classificazione dell'immagine della candela (model_21k):
('Top1: ', 'n02948072 Candle, taper, wax light')
('Top5: ', ['n02948072 Candle, taper, wax light', 'n04581829 Wick, taper', 'n04534895 Vigil light, vigil candle', 'n03005515 Chandlery', 'n02948557 Candlestick, candle holder'])
Risultato della classificazione dell'immagine del gatto (model_21k):
('Top1: ', 'n01318894 Pet')
('Top5: ', ['n01318894 Pet', 'n02122878 Tabby, queen', 'n02122725 Tom, tomcat', 'n02123045 Tabby, tabby cat', 'n02122948 Kitten, kitty'])
Altri modelli pre-addestrati, model_bn e model_v3, forniti dal DMLC, possono essere caricati introducendo piccole variazioni al codice precedente, come riportato negli estratti seguenti.
Secondo modello pre-addestrato model_bn:
...
# pretrained model file settings
prefix = "./datasets/preloaded/model_bn/Inception_BN"
num_round = 39
...
# read textual tags for each classes
# used below to translate the predicted classes in a human-readable way
synset = [l.strip() for l in open('./datasets/preloaded/model_bn/synset.txt').readlines()]
# preprocessing of an image
batch = preprocessing.PreprocessImage_BN('./test-images/candle.jpg', True)
# or batch = preprocessing.PreprocessImage_BN('./test-images/funny-cat.jpg', True)
...
Risultato della classificazione dell'immagine della candela (model_bn):
('Top1: ', 'n02948072 candle, taper, wax light')
('Top5: ', ['n02948072 candle, taper, wax light', 'n03666591 lighter, light, igniter, ignitor', 'n04456115 torch', 'n03729826 matchstick', 'n04266014 space shuttle'])
Risultato della classificazione dell'immagine del gatto (model_bn):
('Top1: ', 'n02123045 tabby, tabby cat')
('Top5: ', ['n02123045 tabby, tabby cat', 'n02124075 Egyptian cat', 'n02123159 tiger cat', 'n03126707 crane', 'n03649909 lawn mower, mower'])
Terzo modello pre-addestrato model_v3:
...
# pretrained model file settings
prefix = "./datasets/preloaded/model_v3/Inception-7"
num_round = 1
...
# read textual tags for each classes
# used below to translate the predicted classes in a human-readable way
synset = [l.strip() for l in open('./datasets/preloaded/model_v3/synset.txt').readlines()]
# preprocessing of an image
batch = preprocessing.PreprocessImage_V3('./test-images/candle.jpg', True)
# or batch = preprocessing.PreprocessImage_V3('./test-images/funny-cat.jpg', True)
...
Risultato della classificazione dell'immagine della candela (model_v3):
('Top1: ', 'n02948072 candle, taper, wax light')
('Top5: ', ['n02948072 candle, taper, wax light', 'n02699494 altar', 'n03666591 lighter, light, igniter, ignitor', 'n03729826 matchstick', 'n04456115 torch'])
Risultato della classificazione dell'immagine del gatto (model_v3):
('Top1: ', 'n03126707 crane')
('Top5: ', ['n03126707 crane', 'n04467665 trailer truck, tractor trailer, trucking rig, rig, articulated lorry, semi', 'n02123045 tabby, tabby cat', 'n02123159 tiger cat', 'n04252225 snowplow, snowplough'])
Tutti i modelli pre-addestrati si basano su configurazioni di reti CNN di varia complessità e profondità (la profondità è il numero degli strati che le compongono). La profondità influenza la capacità della rete di riconoscere ed estrarre automaticamente le caratteristiche che compongono un'immagine (le features).
Performance dei modelli pre-addestrati
Le prestazioni delle reti pre-addestrate fornite da DMLC sono state misurate sul validation set di ILVRC-2012. Per ottenere risultati più pertinenti con il contenuto dell'immagine, le classificazioni sono solitamente limitate a 1000 classi e si considerano i primi 5 o 20 risultati (Top 5 o Top 20) e più raramente il Top 1. Nel caso della rete
model_21ksi è misurata una validation performance del 68.3% su Top 1, 89.0% su Top 5 e 96.0% su Top 20 (ossia su 100 immagini estratte dal validation set, 96 sono state riconosciute correttamente). Se estendessimo la classificazione alla totalità delle classi (27K+), si noterebbe un sensibile calo delle prestazioni e in particolare: 41.9% su Top 1, 69.6% su Top 5 e 83.6% su Top 20. Il secondo modellomodel_bnha una validation performance dell'89.5% su Top 5. Il terzo modellomodel_v3ha un validation perfomance del 76.88% su Top 1 e 93.34% su Top 5. Il secondo e terzo modello sono addestrati sul training set di ILVRC-2012 che consiste di 10 milioni di immagini su circa 10000 classi (è un sottoinsieme dell'archivio ImageNet).
Normalmente, dopo aver preparato un dataset dove potenzialmente ci possono essere immagini di tutte le dimensioni, si procede con semplici operazioni di resize di ciascuna immagine, crop centrale ed altre manipolazioni. Questo trattamento è ovviamente esterno, fatto cioè prima di avviare l'allenamento della rete. Una volta pre-trattate, le immagini sono pronte per essere date in pasto alla rete. Ciascuno dei modelli pre-addestrati richiede un tipo specifico di trattamento delle immagini. Per semplificare ho raccolto le varie funzioni di trattamento nel modulo preprocessing.
Convoluzione
Prima di addentrarci nell'implementazione di un classificatore di immagini basato su CNN, vorrei riassumere alcuni argomenti basilari. Il primo argomento è quello della convoluzione.
Come noto, solitamente ad un'immagine reale viene associata una griglia composta da un elevato numero di piccoli quadrati detti pixel. La figura seguente propone, per esempio, un'immagine in bianco e nero a cui è associata una griglia di dimensioni 5×5 pixel.

La rappresentazione matematica più indicata per una griglia siffatta è una matrice di pari dimensioni (5×5), tale matrice è chiamata matrice di pixel o più in generale matrice di input. Ogni elemento della matrice corrisponde ad un pixel e, nel caso di immagini in bianco e nero, può assumere il valore 1 associato al nero o il valore 0 associato al bianco. Nel caso di un'immagine in tonalità del grigio, la scala di valori ammessi per ogni elemento della matrice è nell'intervallo intero [0,255], dove 0 è associato al nero e 255 al bianco. I valori interi specificano l'intensità luminosa. Le immagini a colori sono rappresentate in modo più complesso perché l'informazione è multidimensionale. Per rappresentare un colore si usa un determinato spazio definito scegliendo un insieme di colori base. Lo spazio di rappresentazione usato più comunemente è quello RGB (Red-Green-Blue). Un'immagine codificata con tre colori è rappresentata da un gruppo di 3 matrici ciascuna corrispondente ad un canale di colore (R,G,B). Ogni elemento di ciascuna matrice può variare su un intervallo intero [0,255] e specifica l'intensità del colore fondamentale (o colore base).
Rappresentazione RGB dei colori
Utilizzando lo spazio RGB in cui ad ogni colore viene associata una terna di valori, che indicano le quantità di rosso, di verde e di blu che consentono di ottenerlo, l'immagine viene rappresentata come una matrice tridimensionale (ovvero un tensore) composta da tre matrici bidimensionali (ognuna delle quali è associata ad un colore fondamentale).
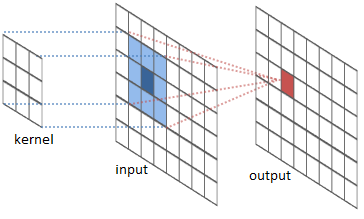
Nella figura sottostante è mostrata una matrice di input che rappresenta l'immagine precedentemente introdotta.
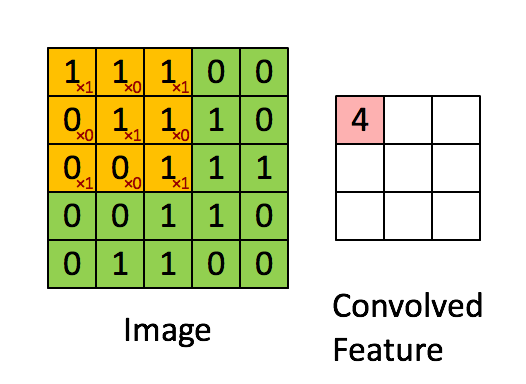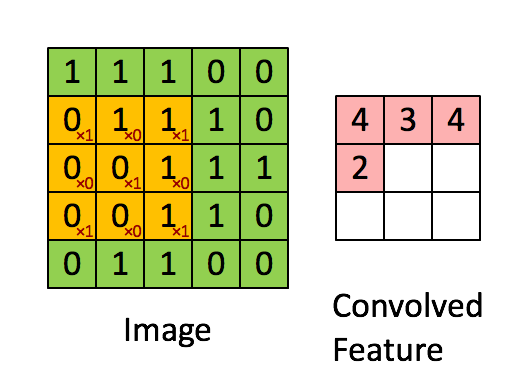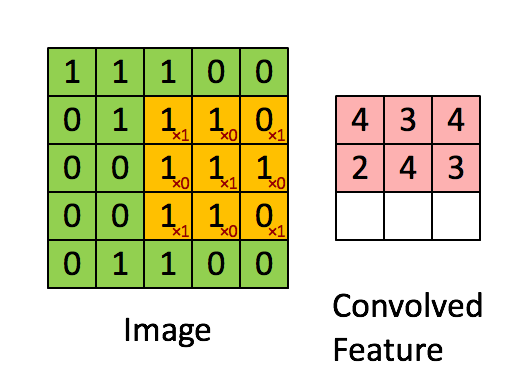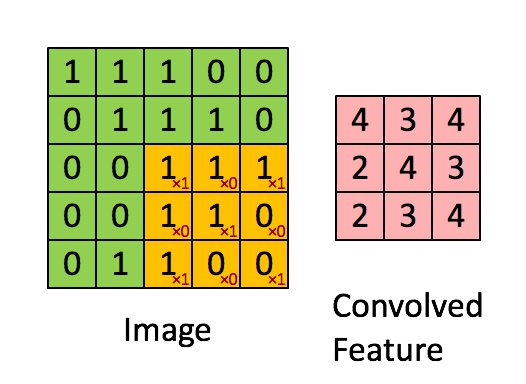
Come mostrato nella figura, supponiamo di far scorrere (dall'alto in basso e da sinistra a destra) sulla matrice di input, una seconda matrice di dimensioni inferiori, per esempio 3×3, così definita:
[1 0 1]
[0 1 0]
[1 0 1]
La matrice che scorre è chiamata kernel o filtro (filter) o feature detector. Man mano che si sposta il filtro lungo l'area della matrice di input, si effettua un'operazione di prodotto membro a membro, cioè un prodotto scalare, fra i valori del filtro e quelli della porzione della matrice al quale è applicato. Il risultato dello scorrimento del filtro si traduce nella generazione di una matrice di convoluzione come quella illustrata in figura (convolved feature). In questo caso la matrice di convoluzione ha dimensioni inferiori alla matrice di input, tuttavia, come vedremo tra breve, con alcuni accorgimenti (p.e. zero-padding) è possibile conservare le dimensioni originali come nella figura seguente.
Nell'ambito della computer grafica esiste una estesa varietà di filtri applicabili ad un'immagine per evidenziarne specifiche particolarità, per esempio con riferimento alla figura seguente (da sinistra a destra): filtro di nitidezza (sharpening) teso a recuperare/aumentare la nitidezza dell'immagine, filtro di sfocatura (blur), filtro di rilevamento contorni (edge detection) e filtro di rilievo (emboss).

Cenni sull'architettura delle reti convoluzionali
Le reti CNN sono di fatto delle reti neurali artificiali. Esattamente come queste ultime, infatti, anche le CNN sono costituite da neuroni collegati fra loro tramite dei rami pesati; parametri allenabili delle reti sono sempre quindi i pesi. Tutto quanto noto per le reti neurali ordinarie, cioè forward/backward propagation e aggiornamento dei pesi, vale anche in questo contesto; inoltre un'intera CNN utilizza sempre una singola funzione di costo differenziabile. Tuttavia le CNN muovono dall'assunzione che ogni loro input abbia una precisa struttura da riconoscere ossia l'input non è una sequenza pre-elaborata di dati, ma il dato nella sua forma originale come ad esempio un'immagine.
Prendendo come esempio la matrice di input 5×5 precedentemente mostrata, una CNN consisterà certamente di uno strato di ingresso composto da 25 neuroni (=5×5) il cui compito è acquisire il valore di input corrispondente ad ogni pixel e trasferirlo allo strato nascosto successivo. Nel caso di una rete multistrato tradizionale le uscite di tutti i neuroni dello strato di ingresso sarebbero connesse ad ogni singolo neurone dello strato nascosto contribuendo così a definire un'architettura completamente connessa (FC, fully connected). Nel caso delle reti CNN, invece, lo schema delle connessioni è significativamente diverso.
Per esempio, assumendo di utilizzare un filtro 3×3 come quello mostrato in precedenza e traslando di un pixel per volta (il passo di traslazione è chiamato stride), è come se suddividessimo la matrice di input in 9 aree di uguale dimensione (questa operazione di suddivisione è anche chiamata piastrellatura dell'immagine). Ciascuna di queste aree definisce un campo ricettivo (receptive field) di un neurone dello strato nascosto. Nello strato nascosto ci saranno 9 neuroni ciascuno avente come input i valori di uno dei 9 campi ricettivi; in particolare per un neurone gli ingressi sono 9 tanti quanti i pixel coperti dal filtro più un ulteriore ingresso (il bias).
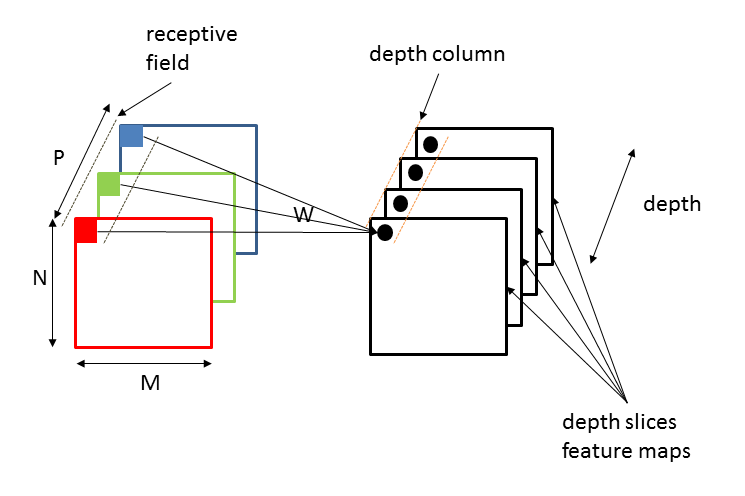
Ad ogni ingresso è associato un peso il cui valore corrisponde ad uno specifico elemento del filtro. In sostanza ogni singolo neurone esegue la convoluzione e la rete è addestrata ad apprendere i pesi (ossia gli elementi del filtro) e il valore del bias per minimizzare la funzione di costo. Abbiamo dunque una batteria o depth slice di 9 neuroni ciascuno collegato ad un campo ricettivo. Ogni neurone ha un bias e 3×3 pesi connessi ad un campo ricettivo: si utilizzano questi stessi pesi e bias per tutti i 9 neuroni appartenente allo stesso depth slice. Questo significa che tutti i neuroni del depth slice applicheranno lo stesso filtro (ossia impareranno a riconoscere la stessa feature), solo collocata diversamente nell'immagine di input. Questo rende le reti convoluzionali adattabili all'invarianza di un'immagine alla traslazione. Bias e pesi condivisi sono chiamati shared weights and biases. Quella che qui ho definito batteria di neuroni o depth slice è anche chiamata mappa di feature (feature map) o mappa di attivazione (activation map).
Ovviamente, per riconoscere in modo efficace un'immagine abbiamo bisogno di più filtri applicati alle stesse regioni (ciascuno dovrà imparare a riconoscere differenti specificità), ciò equivale a dire, nel nostro esempio, utilizzare più depth slice di 9 neuroni in parallelo o, equivalentemente, più mappe di attivazione in parallelo. Il numero di mappe di attivazione è chiamato profondità (depth). In altri termini, la profondità corrisponde anche al numero di neuroni nello strato convoluzionale che sono connessi allo stesso campo ricettivo locale dell'input. L'insieme di neuroni appartenenti a mappe di attivazione diverse, entro lo stesso strato convoluzionale, operanti in parallelo sullo stesso campo ricettivo, è chiamato colonna o depth column.
Per come abbiamo definito le cose nel nostro esempio, l'output di ogni mappa di attivazione è una matrice convoluzionale di dimensioni 3×3. Spesso può essere utile effettuare un'operazione di padding, con degli zeri (da qui zero padding) spazialmente lungo i bordi della matrice di pixel. Nella figura sottostante è mostrato lo zero-padding e (in modo semplificato) il processo convolutivo su uno specifico campo ricettivo mediante un neurone all'interno di una mappa di attivazione.
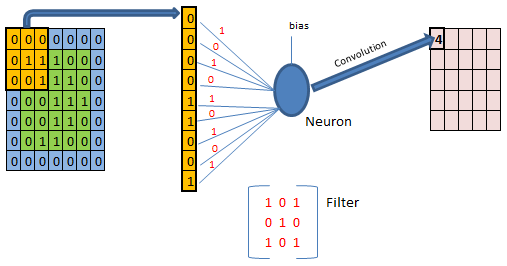
Nell'esempio della figura precedente si è utilizzato uno zero-padding pari a 1. Uno zero-padding a 0 vuol dire che in pratica non si ha nessun padding; con uno zero-padding a 1 significa che tutta la matrice di input avrà, per ciascuna dimensione, un bordo di grandezza 1 di zeri e così via. Lo zero-padding ci consente di ovviare al fatto che le dimensioni del receptive field e dello stride scelti potrebbero non permettere l'intera convoluzione rispetto alle dimensioni della matrice di input.
Una CNN può comporsi di più strati di convoluzione collegati in cascata. L'output di ogni strato di convoluzione è un insieme di matrici di convoluzione (ciascuna generata da una mappa di attivazione). L'insieme di queste matrici definisce un nuovo volume di input utilizzato dalle mappe di attivazione dello strato successivo. Più strati convoluzionali possiede una rete e più feature dettagliate essa riesce ad elaborare.
Solitamente in una rete CNN ogni neurone produce un output tale per cui, superata una certa soglia di attivazione, l'uscita è proporzionale all'ingresso e non limitato superiormente. In termini rigorosi si dice che la funzione di attivazione del neurone è una funzione rampa o ReLU. Una funzione siffatta consente all'uscita di conservare l'intensità dello stimolo di input (input alto=>uscita alta). Inoltre la derivata di una funzione rampa è una funzione gradino ossia una funzione che restituisce uscita costante 1, se il segnale in ingresso è positivo.
Le CNN usano anche degli strati di pooling posizionati subito dopo gli strati convoluzionali. Uno strato di pooling suddivide le matrici convoluzionali in regioni e seleziona un unico valore rappresentativo (valore massimo max-pooling o valore medio average pooling) al fine di ridurre i calcoli degli strati successivi e aumentare la robustezza delle feature rispetto alla posizione spaziale. In sostanza il pooling sottocampiona spazialmente ogni mappa di feature di input.
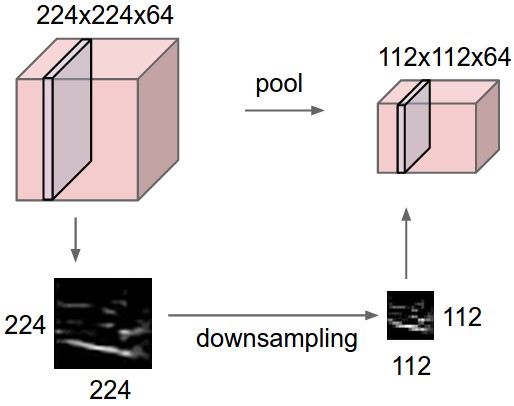
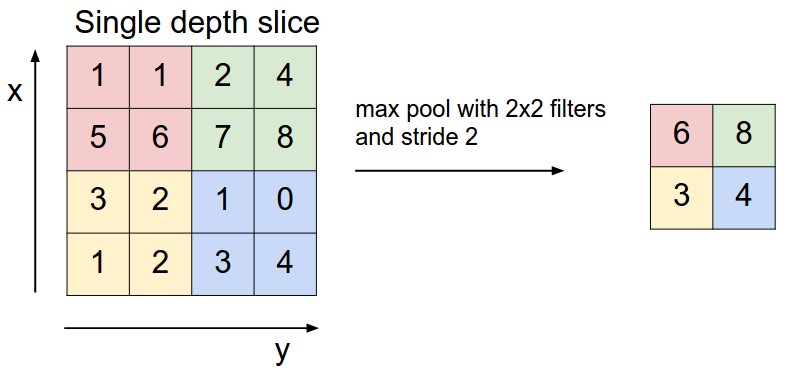
Dopo un'alternanza di strati convoluzionali e di pooling, per i compiti di classificazione, all'ultimo strato della gerarchia è usata una rete neurale tradizionale MLP con funzione di attivazione di tipo softmax (esponenziale normalizzato) per lo strato di uscita. Tale rete è anche conosciuta come multinomial logistic regression. La logistic regression è un classificatore probabilistico lineare. Esso è parametrizzato da una matrice di pesi e da un vettore di bias. Per questo tipo di rete si dimostra che le attivazioni dei neuroni output sono probabilità a posteriori di appartenenza di classe e per questo motivo il numero dei neuroni di uscita è pari al numero di classi.
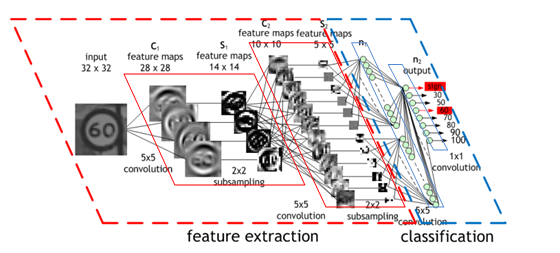
La capacità di una rete neurale convoluzionale può variare in base al numero di strati che essa possiede. Raramente si può trovare un solo strato convoluzionale, a meno che la rete in questione non sia estremamente semplice. Di solito una CNN possiede una serie di strati convoluzionali: i primi di questi, partendo dallo strato di ingresso ed andando verso lo strato di uscita, servono per ottenere feature di basso livello, come ad esempio linee orizzontali o verticali, angoli, contorni vari, ecc; più si scende nella rete, andando verso lo strato di uscita, e più le feature diventano di alto livello, ovvero esse rappresentano figure anche piuttosto complesse come dei volti, degli oggetti specifici, una scena, ecc. In sostanza dunque più strati convoluzionali possiede una rete e più feature dettagliate essa riesce ad elaborare.

Architetture CNN famose
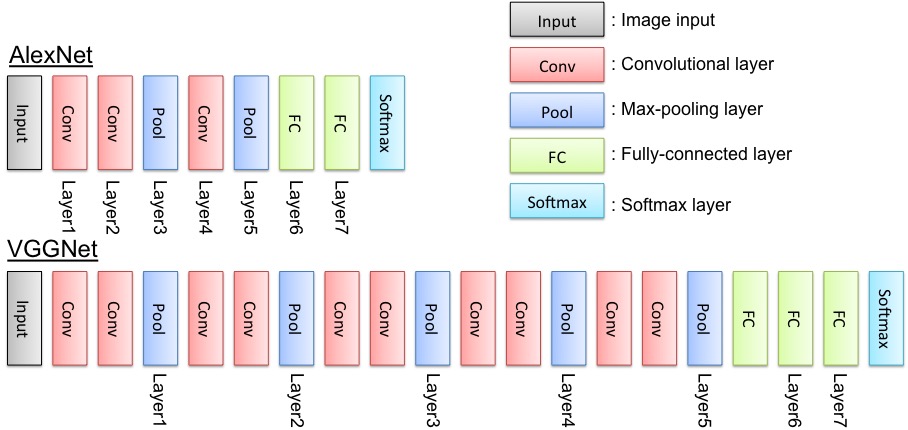
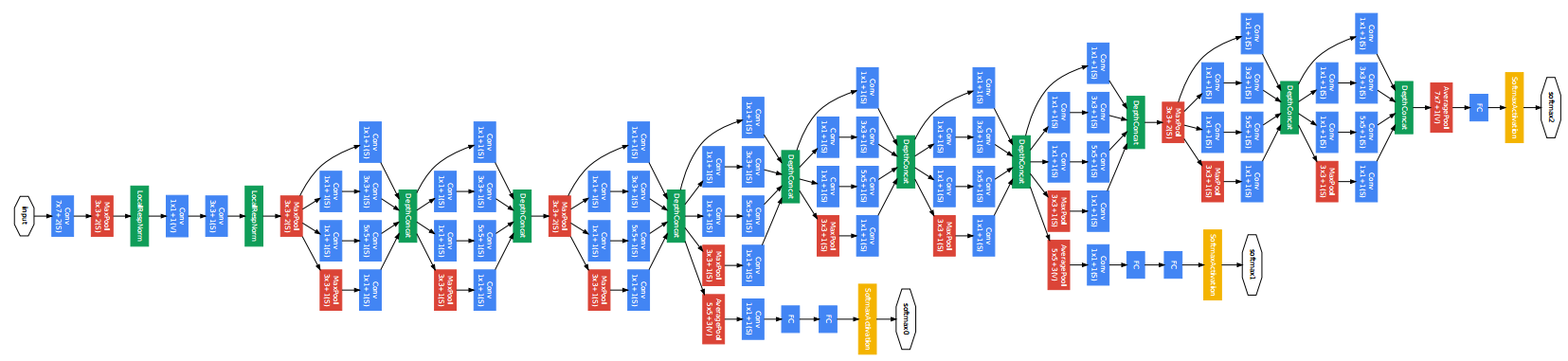
Esistono diverse tipologie di reti CNN, nelle figure seguenti sono mostrate le architetture di tre reti famose: AlexNet, VGGnet, GoogLenet.
La rete AlexNet è una fra le prime reti neurali convoluzionali che ha riscosso un enorme successo. Vincitrice della competizione ILSVRC del 2012, questa rete è stata la prima ad ottenere risultati più che buoni su un dataset molto complicato come ImageNet, utilizzando un'architettura simile a quella descritta in precedenza: una serie di strati convoluzionali seguiti da un'altra serie di strati FC.
VGG è il nome di un team di persone che hanno presentato le proprie reti neurali durante la competizione ILSVRC-2014. Si parla di reti al plurale in quanto sono state create più versioni della stessa rete, ciascuna possedente un numero diverso di strati. In base al numero di strati, ognuna di esse viene solitamente chiamata VGG-n. Tutte queste reti risultano essere più "profonde" rispetto a quella di AlexNet. Per "profonde", si intende il fatto che sono costituite da un numero di strati con parametri allenabili maggiore di AlexNet (p.e. da 11 a 19 strati allenabili in totale).
GoogLeNet fu costruita nel 2014 da un team di dipendenti di Google ed è chiamata così in onore di una delle prime reti convoluzionali, ovvero LeNet. GoogLeNet è la rete che possiede l'architettura più complessa fra quelle accennate. Come si è visto con le reti VGG, il metodo più diretto per aumentare le performance di una CNN è quello di aumentare le loro dimensioni lungo la profondità. Tuttavia per GoogLeNet l'aumento è inteso sia come incremento di profondità, cioè il numero di livelli che la rete possiede, sia come incremento della larghezza della rete, ovvero il numero di strati presenti su uno stesso livello.
Una rete CNN costruita from scratch per il riconoscimento di immagini
A questo punto l'obiettivo è implementare from scratch una CNN dimostrativa in grado di operare su due classi di immagini: cat e airplane. Per la generazione di training, validation e testing set utilizzo il dataset STL-10 che è un sottoinsieme di ImageNet. STL-10 consiste di 13000 immagini a colori di dimensioni 96×96 pixel organizzate in 10 classi più altre 100000 immagini non classificate utilizzabili per apprendimento non supervisionato. Le immagini classificate sono organizzate in 5000 immagini (500 per classe) utilizzabili per il training e 8000 immagini (800 per classe) utilizzabili per validation e testing.
Preparazione di training, validation e testing set
Basandomi sulle funzioni raccolte nel modulo STL-10 Utils ho estratto 2600 immagini relative alle categorie cat e airplane. 1820 (70%) immagini sono usate per il training set, 520 (20%) per il validation set, 260 (10%) per il testing set. Ogni set contiene un numero equivalente di immagini di entrambe le categorie. Ho altresì generato tre file ".lst" per train, validation e testing set ciascuno contenete l'elenco delle immagini e per ciascuna la rispettiva classe di appartenenza (0 per airplane e 1 per cat). Infine, utilizzando il tool im2rec, distribuito con il framework MXNet, ho raggruppato le immagini in due archivi binari (aventi estensione ".rec"). Ho configurato il tool im2rec in modo da eseguire contestualmente alla creazione dell'archivio anche il resize a 28×28 e la conversione in grayscale.
Al termine i dataset sono così organizzati:
train.lst: tabella associativa tra classi e immagini del training setvalidation.lst: tabella associativa tra classi e immagini del validation settest.lst: tabella associativa tra classi e immagini del testing settrain_28_gray.rec: archivio delle immagini 28×28 grayscale di trainingval_28_gray.rec: archivio delle immagini 28×28 grayscale di validationtest_28_gray.rec: archivio delle immagini 28×28 grayscale di test
Per approfondimenti sull'impiego di im2rec e il formato dei file ".lst" consultare MXNet Python Data Loading API.
Creazione e training della rete CNN
Nel blocco seguente, eseguo anzitutto le importazioni delle librerie necessarie tra cui spicca, ovviamente, il wrapper python per MXNet. Successivamente creo due istanze della classe mx.io.ImageRecordIter. Gli oggetti di tipo ImageRecordIter sono essenzialmente degli iteratori su blocchi di immagini. Il primo iteratore è configurato per lavorare sulle immagini del training set, il secondo sulle immagini del validation set.
Nel caso del training set, l'iteratore è costruito affinché esegua casualmente dei ritagli rand_crop=True e dei ribaltamenti orizzontali rand_mirror=True delle immagini (ciò aiuta la rete ad apprendere in modo più robusto); questi trattamenti delle immagini non sono richiesti sul validation set. Su entrambi i set imposto la dimensione dell'immagine data_shape = (1,28,28) dove 1 rappresenta il numero di canali delle immagini e i successivi valori rappresentano rispettivamente larghezza e altezza. Imposto inoltre batch_size = 10 su entrambi i set. batch_size rappresenta il numero di elementi di input, cioè di immagini in questo caso, che vengono processate nella rete di volta in volta (importante per l'allenamento di una rete).
# import library
# neural network performance analysis
import seaborn as sns
import mxnet as mx
import sys,logging,numpy,random,csv
from sklearn.metrics import roc_auc_score, auc, precision_recall_curve, roc_curve, average_precision_score
train = mx.io.ImageRecordIter(
path_imgrec = './datasets/stl10/images/train_28_gray.rec',
path_imglist="./datasets/stl10/images/train.lst",
data_shape = (1,28,28),
batch_size = 10,
rand_crop = True,
rand_mirror = True
)
val = mx.io.ImageRecordIter(
path_imgrec = './datasets/stl10/images/val_28_gray.rec',
path_imglist="./datasets/stl10/images/val.lst",
rand_crop = False,
rand_mirror = False,
data_shape = (1,28,28),
batch_size = 10
)
Nel blocco seguente: configuro il logger per poter giovare di una visualizzazione in debug durante l'addestramento. Per la riproducibilità dei risultati imposto il generatore di numeri casuali specificando il valore del seme (seed) mx.random.seed(100). Imposto inoltre devs = mx.cpu() avendo cura di indicare quale processore utilizzare per l'elaborazione (nel mio caso la CPU).
# configure logger
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
# set seeds for reproducibility
mx.random.seed(100)
# device used. CPU in my case.
devs = mx.cpu()
Finalmente, nel blocco seguente, specifico l'architettura della rete CNN in modalità "dichiarativa" (si noti l'assenza di qualsiasi riferimento a variabili con dati).
Ho 4 strati con parametri allenabili: una serie di 2 strati convoluzionali seguita da 2 strati FC (completamente connessi). Ogni strato convoluzionale è seguito da uno strato tanh act_type="tanh" e da uno strato di MAX pooling pool_type="max" (l'attivazione tanh su questa tipologia di rete risulta preferibile alla ReLU). Tutti gli strati di pooling hanno una regione di estensione 2×2 kernel=(2,2) ed uno stride pari a 2 stride=(2,2): ciò vuol dire che si utilizza sempre un overlapping pooling. Tale scelta è dovuta al fatto che questo tipo di pooling incrementa leggermente le prestazioni della rete rispetto al normale pooling senza overlapping. Dei 2 strati FC il primo possiede 500 neuroni num_hidden=500, mentre l'ultimo possiede 2 unità num_hidden=2 corrispondenti al numero di classi di nostro interesse (cat e airplane).
Una singola fase di forward propagation implica le seguenti principali operazioni: il primo strato convoluzionale accetta in input una struttura dati 28x28x1 che è la matrice di input (tipicamente il generico input di uno strato convoluzionale è anche chiamato volume) e ad essa applica 20 filtri num_filter=20, ognuno di dimensioni 5×5 kernel=(5,5) con uno stride di 1 (valore di default) e nessun zero-padding (valore di default), ottenendo 20 mappe di attivazione di dimensione 24×24.
Il secondo strato convoluzionale prende in input il volume 12x12x20 ottenuto dal volume 24x24x20 a cui sono state applicate le funzioni tanh ed overlapping pooling (quest'ultima produce il volume di dimensioni ridotte). Il secondo strato convoluzionale convolve il volume 12x12x20 con 50 kernel di dimensione 5x5x20, uno stride pari a 1 e nessun zero-padding, ottenendo un volume 8x8x50. Successivamente dopo le operazioni di tanh, viene applicato un altro strato di pooling identico al precedente e si ottiene un volume 4x4x50.
A questo punto il primo dei 2 strati FC possedente 500 neuroni effettua il suo normale lavoro, cioè i vari prodotti e somme per ottenere le attivazioni dei suoi 500 neuroni ottenendo un vettore in uscita di dimensioni 1×500. Analoga cosa con il secondo ed ultimo strato FC, il quale possedendo 2 unità, il numero di classi di nostro interesse, produce in output un vettore di dimensioni 1×2.
La funzione di attivazione softmax dei neuroni in uscita NN_model = mx.symbol.SoftmaxOutput(data=fc2, name='softmax') crea ogni output in [0,1] con somma di tutti gli output pari a 1, consentendo di interpretare la risposta della rete come stime di probabilità.
data = mx.symbol.Variable('data')
# 1st convolutional layer
conv1 = mx.symbol.Convolution(data=data, kernel=(5,5), num_filter=20)
tanh1 = mx.symbol.Activation(data=conv1, act_type="tanh")
pool1 = mx.symbol.Pooling(data=tanh1, pool_type="max", kernel=(2,2), stride=(2,2))
# 2nd convolutional layer
conv2 = mx.symbol.Convolution(data=pool1, kernel=(5,5), num_filter=50)
tanh2 = mx.symbol.Activation(data=conv2, act_type="tanh")
pool2 = mx.symbol.Pooling(data=tanh2, pool_type="max",kernel=(2,2), stride=(2,2))
# 1st fully connected layer
flatten = mx.symbol.Flatten(data=pool2)
fc1 = mx.symbol.FullyConnected(data=flatten, num_hidden=500)
tanh3 = mx.symbol.Activation(data=fc1, act_type="tanh")
# 2nd fully connected layer
fc2 = mx.symbol.FullyConnected(data=tanh3, num_hidden=2)
# Output. Softmax output since we'd like to get some probabilities.
NN_model = mx.symbol.SoftmaxOutput(data=fc2, name='softmax')
Dopo la definizione in modalità dichiarativa dell'architettura della rete passo alla creazione del modello mediante l'istanziazione della classe mx.model.FeedForward.
In fase di costruzione del modello specifico il contesto di esecuzione ctx=devs (la CPU nel mio caso, ma in casi più complessi potrebbe essere una lista di GPU), l'architettura della rete symbol=NN_model, il numero di epoche num_epoch=400, il valore di learning rate learning_rate=0.0001. Il learning rate è un fattore moltiplicativo per il gradiente; serve a specificare/regolare il grado di apprendimento, o meglio di aggiornamento, rispetto ai pesi e al bias.
Un altro parametro specificato è il momentum momentum=0.9. Il momentum indica il peso dell'aggiornamento precedente dei parametri durante l'algoritmo di discesa del gradiente (gradient-descent). Solitamente si lascia sempre il valore 0.9 in quanto è stato visto che in questo modo si ottengono buoni risultati.
Infine, l'ultimo parametro specificato è il weight decay weight_decay=0.00001 è un parametro che influenza il termine di regolarizzazione che appare nella formula per il calcolo della funzione di costo. Il weight decay regola l'effetto del fattore di regolarizzazione: un valore elevato rende la rete incapace di trattare le non linearità annullando l'effetto di gran parte dei pesi (in pratica è come se utilizzassimo una rete più semplice), valori bassi rendono la rete più robusta attenuando moderatamente l'effetto dei pesi ma consentendo di trattare le non linearità senza incorrere in overfitting.
model = mx.model.FeedForward(
ctx = devs,
symbol = NN_model,
num_epoch = 400,
learning_rate = 0.0001,
momentum = 0.9,
wd = 0.00001
)
Il passaggio successivo consiste nell'avviare l'apprendimento della rete mediante l'invocazione della funzione model.fit(...).
fit è una funzione definita nella classe mx.model.FeedForward e, all'invocazione richiede la specificazione di alcuni parametri. Anzitutto è necessario fornire il training set X=train e il validation set eval_data=val. Al termine nell'esecuzione di ogni batch è possibile collegare l'invocazione di una funzione batch_end_callback=mx.callback.Speedometer(batch_size=10) in grado di visualizzare la velocità di apprendimento (numero di campioni processati al secondo). La funzione Speedometer utilizza l'elenco di funzioni eval_metric=['accuracy',roc_auc_score] per calcolare metriche e visualizzarne i valori al termine di ogni batch sul training set.
Al termine dell'esecuzione di ogni epoca è possibile collegare un'ulteriore funzione in grado di salvare i parametri appresi dalla rete in un checkpoint file su disco epoch_end_callback=mx.callback.do_checkpoint(prefix="rot_tanh_28_5_400",period=1) dove prefix è una stringa arbitraria che è utilizzata per generare automaticamente il nome del file di checkpoint (con indice numerico progressivo) e period indica ogni quante epoche deve essere eseguito il salvataggio.
model.fit(X=train,
eval_data=val,
eval_metric=['accuracy',roc_auc_score],
batch_end_callback=mx.callback.Speedometer(batch_size=10, frequent=50),
epoch_end_callback=mx.callback.do_checkpoint(prefix="rot_tanh_28_5_400", period=10)
)
Iter 12800, Minibatch Loss= 0.305791, Training Accuracy= 0.90625
Iter 25600, Minibatch Loss= 0.252651, Training Accuracy= 0.92969
Iter 38400, Minibatch Loss= 0.203888, Training Accuracy= 0.93750
Iter 51200, Minibatch Loss= 0.097179, Training Accuracy= 0.96094
Iter 64000, Minibatch Loss= 0.091221, Training Accuracy= 0.97656
Iter 76800, Minibatch Loss= 0.176814, Training Accuracy= 0.95312
Iter 89600, Minibatch Loss= 0.110684, Training Accuracy= 0.96875
Optimization Finished!
Testing Accuracy: 0.992188
Dopo aver definito i dati inputs e la nostra RNN, è tempo di iniziare l'ALLENAMENTO: prima, facciamo la nostra sessione per usarla per far sì che i nostri calcoli avvengano, eseguiamo i nostri dati in modo sequenziale, li dividiamo in pezzi ogni pezzo è dimensionato dalla dimensione del batch che abbiamo definito, poi prendiamo ogni pezzo e lo diamo in pasto al nostro ottimizzatore e calcoliamo la nostra precisione ed errore e lo ripetiamo dando nuovi blocchi, e così via in questo processo la nostra precisione migliora sempre di più man mano che la alimentiamo sempre di più, la nostra precisione migliora.
Curva ROC e metriche di valutazione
La curva ROC (Receiver Operating Characteristics) è una tecnica statistica che permette di misurare l'accuratezza di una rete lungo tutto il range dei valori possibili. L'area sottostante alla curva ROC (AUC, acronimo dei termini inglesi Area Under the Curve) è una misura di accuratezza. Se un'ipotetica rete addestrata discriminasse perfettamente tutti gli input, l'area della curva ROC avrebbe valore 1, cioè il 100% di accuratezza. Nel caso in cui la rete non discriminasse per niente gli input, la curva ROC avrebbe un'area di 0.5 (o 50%) che coinciderebbe con l'area sottostante la diagonale del grafico. L'area sotto la curva può assumere valori compresi tra 0.5 e 1.0. Tanto maggiore è l'area sotto la curva (cioè tanto più la curva si avvicina al vertice del grafico) tanto maggiore è il potere discriminante della rete.
Nella figura seguente sono mostrati due grafici che ci consentono di analizzare velocemente le prestazioni della rete comparate su training e validation set nello spazio ROC e nello spazio PR con indicazione dell'AUC come metrica di valutazione.
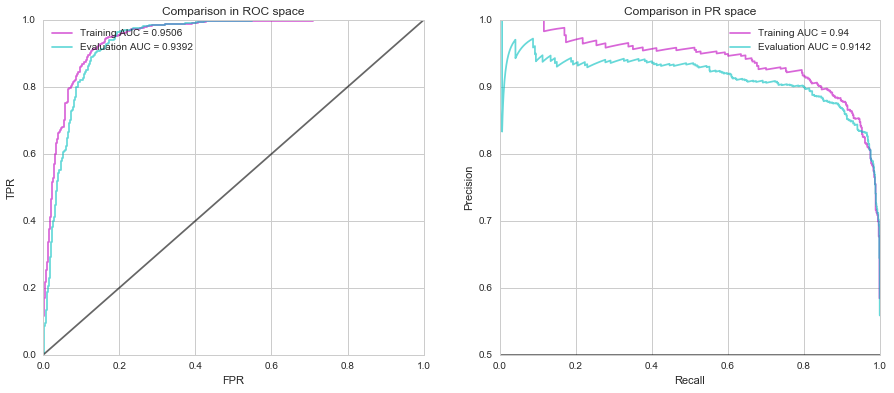
Finalmente è arrivato il momento di provare le capacità predittive della rete. Utilizzo il testing set composto di 260 immagini equamente distribuite sulle due categorie. Questo set include immagini che non sono mai state sottoposte alla rete. Le immagini possono essere estratte dall'archivio binario ".rec" e, mediante il file ".lst", è possibile risalire alla classe di appartenenza di ciascuna. Ciclando su ogni immagine invoco la funzione model.predict per ottenere l'elenco di probabilità per ciascuna delle due classi. In breve, questi i risultati che ho ottenuto:
success: 237, total: 260, cat: 129, plane 108
Dunque, su 260 immagini il 91% circa (237 su 260) è stato correttamente riconosciuto, con il 99% dei successi su cat e l'83% su airplane.
Risultato di notevole interesse e certamente migliorabile lavorando sui parametri della rete. Ma questa è un'altra storia.
Riferimenti e approfondimenti
Per ulteriori approfondimenti, queste sono alcune delle fonti consultate: