
Dataset di esempio
Il dataset che ho usato per verificare il funzionamento delle due catene Knime è scaricabile seguendo il link:
corpus-ML-58-082816.csvIl dataset è memorizzato in formato CSV e contiene un corpus di documenti. Ogni documento è codificato come una stringa e corrisponde ad una linea del file CSV.
Implementazione con nodi nativi Knime (Esempio 1)
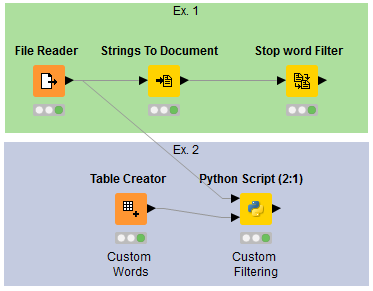
Nel primo esempio (Ex. 1) abbiamo una catena di tre elementi:
Struttura del workflow
File Reader: Per la lettura del CSV e la generazione di una tabella con una stringa per riga (una stringa corrisponde al testo di un documento). La tabella di output sarà poi usata ed estesa dai nodi seguenti.
Strings to Document: Per la conversione di ogni stringa in un oggetto di tipo
Text Document(tipo interno di Knime). L'output consiste in una tabella contenente una colonna con gli oggettiText Document(uno per riga).Stop word Filter: Cicla su ogni riga, legge gli oggetti di tipo
Text Documente provvede alla rimozione delle stop word dal contenuto, aggiungendo una nuova colonna con oggettiText Documentfiltrati.
Caratteristiche del nodo Stop word Filter
Nel nodo Stop word Filter è possibile selezionare:
- Stop list built-in per la lingua desiderata (incluso quella Italiana)
- Stop list custom memorizzata come file su disco
Nota importante: Non è possibile impiegare contemporaneamente due stop list: una built-in e una custom. Nel caso di impiego combinato di più liste, è necessario collegare in cascata più nodi
Stop word Filter. Ulteriori processazioni e filtraggi richiederanno il collegamento in cascata di altri nodi di elaborazione, secondo lo stile classico di Knime.
Implementazione con Python Script (Esempio 2)
Nel secondo esempio (Ex. 2) si è incapsulato del codice Python nel nodo wrapper Scripting > Python > Python Script (2:1).
Vantaggi dell'approccio Python
Il codice incapsulato utilizza:
- Package esterno per la rimozione delle stop word (libreria stop-words)
- Lista custom creata mediante il nodo
Table Creatorin Knime - Processazione diretta sulle stringhe (senza conversione a
Text Document)
Funzionalità aggiuntive
Per scopo dimostrativo, il codice incapsulato è stato ulteriormente esteso aggiungendo:
- Parsing che tiene conto della punteggiatura
- Filtraggio sulla lunghezza minima delle parole
- Rimozione di token consistenti di soli numeri o sola punteggiatura
Codice Python integrato
Il codice incapsulato nel secondo esempio:
from nltk.tokenize import wordpunct_tokenize
import string
import pandas as pd
from stop_words import get_stop_words
min_word_len=3
input_column_name="Col0"
custom_column_name="stopword"
stoplist=get_stop_words('italian')
output_table=pd.DataFrame(columns=[input_column_name])
for index, row in input_table_1.iterrows():
filtered_corpus = [word for word in wordpunct_tokenize(row[input_column_name].lower())
if word not in stoplist
and not word in input_table_2[custom_column_name].values
and word not in string.punctuation
and len(word)>min_word_len
and not word.isdigit()]
output_table.loc[len(output_table)]=" ".join(str(item) for item in filtered_corpus)
Analisi del codice
Il codice implementa un pipeline di filtraggio completo che:
- Tokenizza il testo usando
wordpunct_tokenize - Converte in minuscolo per uniformità
- Filtra le stop word italiane
- Rimuove parole della lista custom
- Esclude la punteggiatura
- Applica filtro lunghezza minima
- Elimina token numerici
Confronto tra gli approcci
Approccio nativo Knime
Vantaggi:
- ✅ Interfaccia grafica intuitiva
- ✅ Nessuna programmazione richiesta
- ✅ Integrazione nativa con l'ecosistema Knime
- ✅ Visualizzazione immediata dei risultati
Limitazioni:
- ⚠️ Limitato a stop list predefinite o singole liste custom
- ⚠️ Richiede conversione a
Text Document - ⚠️ Workflow più lungo per operazioni complesse
Approccio Python Script
Vantaggi:
- ✅ Flessibilità massima nella logica di filtraggio
- ✅ Accesso a librerie Python specializzate
- ✅ Combinazione di multiple stop list
- ✅ Processazione avanzata (regex, parsing complesso)
- ✅ Codice compatto per operazioni multiple
Considerazioni:
- 🔧 Richiede conoscenza di Python
- 🔧 Debug più complesso rispetto all'interfaccia grafica
Vantaggi dell'integrazione Python-Knime
La sinteticità e praticità di Python consentono di:
- Snellire il flusso di esecuzione
- Accedere ad una immensa varietà di package del mondo Python
- Implementare logiche complesse in poche righe
- Mantenere la comodità dell'interfaccia Knime per il workflow generale
Interazione tecnica
L'interazione tra Python e Knime si fonda sullo scambio di oggetti DataFrame della libreria pandas, rendendo l'integrazione naturale e efficiente.
pandasOttimizzazioni e estensioni
Il codice presentato è perfettibile, parametrizzabile ed estendibile. Possibili miglioramenti includono:
Parametrizzazione
- Configurazione esterna dei parametri di filtraggio
- Selezione dinamica della lingua
- Controllo granulare delle regole di filtraggio
Estensioni funzionali
- Stemming e lemmatizzazione
- Riconoscimento di entità nominate
- Analisi della frequenza dei termini
- Normalizzazione avanzata del testo
Performance
- Ottimizzazione per grandi dataset
- Parallelizzazione del processing
- Caching delle stop list
Conclusioni
Questo esempio dimostra la potenza dell'integrazione tra Python e Knime per il text processing. Mentre l'approccio nativo offre semplicità e immediatezza, l'integrazione con Python apre possibilità praticamente illimitate per implementazioni avanzate di NLP.
La scelta dell'approccio dipende da:
- Complessità dei requisiti di filtraggio
- Esperienza del team con Python
- Necessità di personalizzazione avanzata
- Volume e varietà dei dati da processare
L'integrazione Python-Knime rappresenta il meglio dei due mondi: la potenza e flessibilità di Python con l'usabilità e la gestione visuale dei workflow di Knime.
Questo è tutto. Felice utilizzo!